



HashSet — це одна з найпопулярніших реалізацій інтерфейсу Set у Java, яка забезпечує зберігання унікальних елементів і дозволяє ефективно управляти колекцією даних.
Основний принцип роботи HashSet базується на використанні механізму хешування, що дозволяє здійснювати операції додавання, пошуку та видалення елементів в більшості випадків з середньою складністю O(1). Завдяки цьому HashSet часто використовується у задачах, де важлива висока продуктивність і ефективне управління пам’яттю. Якщо ви хочете отримати більш поглиблені знання у JAVA, зверніть увагу на курс онлайн-академії FoxmindEd.
У цій статті ми розглянемо приклади використання HashSet у Java та як саме він працює під капотом, зокрема, як відбувається зберігання елементів, розподіл по бакетах, і як методи hashCode та equals впливають на його роботу.
Внутрішня структура HashSet
HashSet в Java побудований на основі HashMap. Кожен елемент фактично зберігається як ключ (key) у внутрішньому HashMap, а значенням (value) для цього ключа виступає спеціальна заглушка. Елементи зберігаються у так званих бакетах — комірках хеш-таблиці, де кожен бакет відповідає певному хеш-коду. Це дозволяє HashSet зберігати тільки унікальні елементи, оскільки HashMap не допускає однакових ключів.
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
private transient HashMap<E, Object> map;
// Константа-заглушка, яка використовується замість значення
private static final Object PRESENT = new Object();
public HashSet() {
map = new HashMap<>();
}
// інші конструктори та методи
// при додаванні елемента замість value додається заглушка
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
// інші методи
}
Роль hashCode та equals
Кожен об’єкт у Java має метод hashCode, який повертає ціле число — хеш-код. Цей код використовується для визначення «бакета», в який буде поміщений об’єкт у хеш-таблиці.
- Коли ви додаєте елемент у HashSet, метод hashCode викликається для цього елемента, щоб обчислити його хеш-код.
- На основі цього хеш-коду HashSet (внутрішній HashMap) визначає індекс бакета, де буде зберігатися елемент.
- Якщо в цьому бакеті вже є елементи, то можливе виникнення колізії, коли кілька елементів мають однаковий хеш-код і, відповідно, потрапляють в один і той самий бакет.
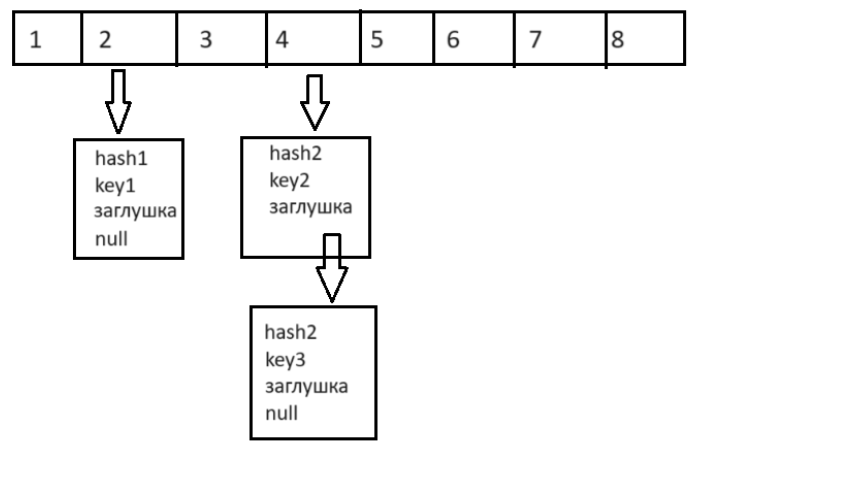
Хороший метод hashCode має забезпечувати рівномірний розподіл об’єктів по бакетах, що зменшує ймовірність колізій і підвищує ефективність HashSet.
Проте, якщо колізія вже виникла, метод equals використовується для перевірки рівності двох об’єктів.
Процес порівняння:
- Якщо два об’єкти мають однаковий хеш-код і потрапляють в один бакет, HashSet викликає метод equals, щоб перевірити, чи є ці об’єкти еквівалентними.
- Якщо метод equals повертає true, новий елемент не додається, оскільки HashSet не допускає дублювання.
- Якщо метод equals повертає false, новий елемент додається в HashSet, навіть якщо він потрапив в той самий бакет, що й інший елемент.
Якщо у класа не перевизначити методи equals і hashCode, порівняння об’єктів буде здійснюватися за їхньою «посилковою рівністю» та стандартним хеш-кодом та методом equals, який генерується класом Object.
Основні операції в HashSet
HashSet надає кілька основних операцій, які дозволяють ефективно працювати з унікальними елементами. Давайте розглянемо ці операції детальніше.
Додавання (add)
Коли ви додаєте елемент у HashSet за допомогою методу add(E e), HashSet викликає внутрішній метод put у HashMap. Якщо такого елемента (ключа) ще немає у HashMap, він додається у відповідний бакет, а метод add повертає true, що означає успішне додавання.
Якщо елемент уже є у HashSet, новий елемент не додається, і метод add повертає false. Це відбувається через те, що HashSet не допускає дублювання елементів. Унікальність забезпечується механізмом перевірки наявності ключа у внутрішньому HashMap.
Перевірка наявності (contains)
Метод contains(Object o) перевіряє, чи міститься даний елемент у HashSet. Він викликає метод containsKey у внутрішньому HashMap, який перевіряє, чи існує ключ з таким же значенням.
Якщо елемент є у HashSet, метод contains повертає true, в іншому випадку — false.
Видалення (remove)
Метод remove(Object o) видаляє елемент з HashSet. Він викликає метод remove у внутрішньому HashMap, який видаляє відповідний ключ з таблиці бакетів.
Якщо елемент був успішно видалений, метод remove повертає true. Якщо елемента не було в HashSet, метод повертає false.
Ітерація по елементах
HashSet дозволяє ітеруватися по всіх елементах, використовуючи такі методи, як iterator() або цикл for-each.
HashSet<String> set = new HashSet<>();
set.add("Apple");
set.add("Banana");
set.add("Orange");
for (String fruit : set) {
System.out.println(fruit);
}Метод iterator() корисний для перебору колекцій, коли вам потрібно мати більший контроль над процесом ітерації, ніж це можливо у циклі for-each. Наприклад, він дозволяє видаляти елементи під час ітерації, що не можна зробити в for-each циклі.
Iterator має три основні методи:
- hasNext()
Повертає true, якщо в колекції є ще елементи, які можна переглянути, або false, якщо всі елементи вже пройдені.
- next()
Повертає наступний елемент у колекції. Якщо більше елементів немає, цей метод може викликати NoSuchElementException.
- remove()
Видаляє останній елемент, що був повернений методом next() з колекції. Цей метод можна викликати тільки один раз після кожного виклику next(). Якщо колекція не підтримує видалення елементів через ітератор, виклик цього методу викличе UnsupportedOperationException.
HashSet<String> set = new HashSet<>();
set.add("Apple");
set.add("Banana");
set.add("Orange");
Iterator<String> iterator = set.iterator();
while (iterator.hasNext()) {
String fruit = iterator.next();
System.out.println(fruit);
}Особливості відсутності порядку зберігання елементів:
HashSet не гарантує збереження порядку елементів. Це означає, що елементи можуть зберігатися і повертатися в довільному порядку, який не відповідає порядку їх додавання.
Причина цього в тому, що елементи розподіляються по бакетах на основі їх хеш-кодів, а не на основі їх порядку додавання. Якщо вам потрібен збережений порядок, можна використовувати інші реалізації Set, такі як LinkedHashSet, яка зберігає порядок додавання.
Висновок
HashSet — це ідеальний вибір для ситуацій, коли вам потрібно зберігати унікальні елементи без дотримання певного порядку. HashSet самостійно видаляє дублікати і гарантує, що кожен елемент буде представлений у множині лише один раз.
Крім того, HashSet забезпечує високу продуктивність для основних операцій додавання, видалення та перевірки наявності елементів. Завдяки використанню хеш-таблиці, ці операції виконуються в середньому за константний час — O(1). Це робить HashSet дуже ефективним у задачах, де важливо швидко знаходити та обробляти елементи.
Однак варто пам’ятати, що HashSet не гарантує порядок зберігання елементів. Елементи можуть зберігатися і повертатися в довільному порядку, який визначається їх хеш-кодами, а не порядком додавання. Якщо порядок елементів має значення для вашої задачі, то HashSet може не відповідати вашим вимогам.
У таких випадках варто звернути увагу на інші колекції, які можуть бути більш підходящими.
TreeSet: Якщо вам потрібно зберігати унікальні елементи, але при цьому важливо, щоб вони були відсортовані, використовуйте TreeSet. На відміну від HashSet, який не гарантує порядок елементів, TreeSet підтримує природний порядок або порядок, заданий компаратором, і забезпечує складність O(log n) для основних операцій.
LinkedHashSet: Якщо вам потрібна унікальність елементів, але також важливо зберегти порядок їх додавання, використовуйте LinkedHashSet. Ця колекція зберігає елементи в тому порядку, в якому вони були додані, при цьому забезпечуючи ефективність операцій на рівні HashSet.

У вас залишилися запитання про hashset у Java? Запитуйте в коментарях нижче.