



HashMap Java – это одна из самых популярных структур данных, которая позволяет хранить пары “ключ-значение” и обеспечивает быстрый доступ к значениям с помощью ключей. Вкратце напомню про курсы Java start как стартовый курс для наработки базовых знаний и JAVA – для выхода на уровень Junior. Присоединяйтесь, друзья. А пока – двигаемся дальше:
Внутренняя структура HashMap
HashMap работает с помощью массива, который содержит так называемые “бакеты” (buckets) – это своеобразные ячейки, где хранятся элементы. Если посмотреть на код HashMap, то можно увидеть, что он содержит в себе массив Node[]. Node – это класс, который реализует интерфейс Map.Entry и содержит четыре основных поля:
- hash: сохраняет предварительно вычисленный хеш-код ключа.
- key: сам ключ, по которому происходит поиск значения.
- value: значение, ассоциированное с ключом.
- next: ссылка на следующий элемент в случае коллизии (цепочка элементов).
Внутреннее строение класса HashMap:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}Когда выполняется добавление элементов в HashMap в Java, вычисляется хэш-код ключа, и на его основе определяется индекс в массиве бакетов, куда этот элемент будет помещен. Если бакет с этим индексом пуст, новый Node просто добавляется в него. Эта операция очень быстрая, поскольку вычисление индекса массива из хеш-кода выполняется за константное время – O(1).
Коллизия
В идеальном случае каждый элемент должен был бы иметь свой личный бакет, но из-за ограниченности возможных значений хеш-кодов часто возникают коллизии, когда разные ключи попадают в один и тот же бакет, потому что у них вычисляется одинаковый хеш-код. Поэтому если бакет уже содержит другие элементы, происходит сравнение ключей с помощью equals. Если они одинаковые – идет изменение значения (value). Если ключи разные – добавляется новый элемент в цепочку.
В случае коллизий, когда несколько элементов хранятся в одном бакете в виде цепочки (связанного списка), сложность поиска в худшем случае увеличивается до O(n), где n – количество элементов в этой цепочке.
Однако в среднем, благодаря равномерному распределению хеш-кодов и хорошей реализации hashCode(), сложность поиска остается O(1) для большинства случаев.
Рассмотрим пример. Предположим, что у вас есть два ключа, которые, после вычисления хеш-кода, имеют одинаковый индекс в массиве бакетов. Первый ключ (например, “key1”) добавляется в пустой бакет под номером 2, создавая новый Node. Когда вы добавляете второй ключ (например, “key2”), который имеет тот же хэш-код и, соответственно, индекс в массиве, HashMap помещает этот новый элемент в тот же бакет, но уже в виде нового Node, который ссылается на предыдущий.
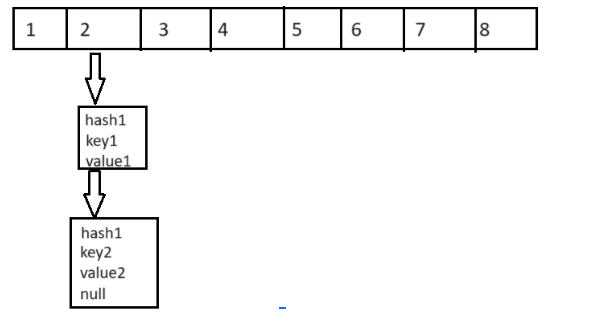
Node<K,V> firstNode = new Node<>(hash1, key1, value1, null);
Node<K,V> secondNode = new Node<>(hash1, key2, value2, firstNode);В случае, когда вы добавляете два элемента с одинаковыми ключами, но с разными значениями, HashMap просто заменяет значение первого элемента на новое значение, то есть перезаписывает его.
Допустим, в хеш карте уже есть элемент с ключом “key1” и значением “value1”.
Node<K,V> firstNode = new Node<>(hash1, key1, value1, null);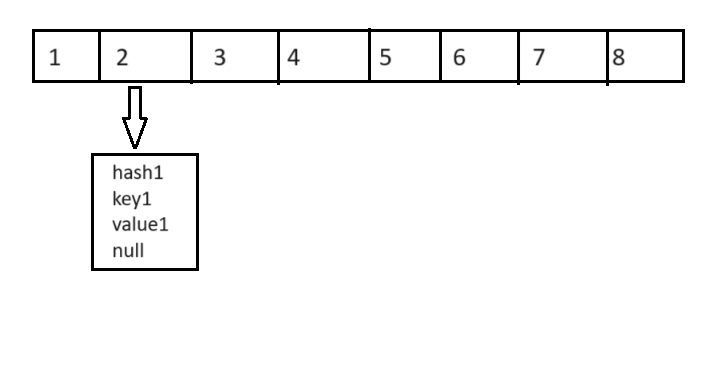
Поэтому, когда вы добавляете второй элемент с таким же ключом, но с другим значением, HashMap находит существующий ключ “key1” в том же бакете (поскольку хеш-коды совпадают) и выполняет проверку equals(), чтобы убедиться, что ключи равны. Поскольку они равны, значение value1 заменяется новым значением “value2”, и цепочка не меняется:
Node<K,V> firstNode = new Node<>(hash1, key1, value2, null);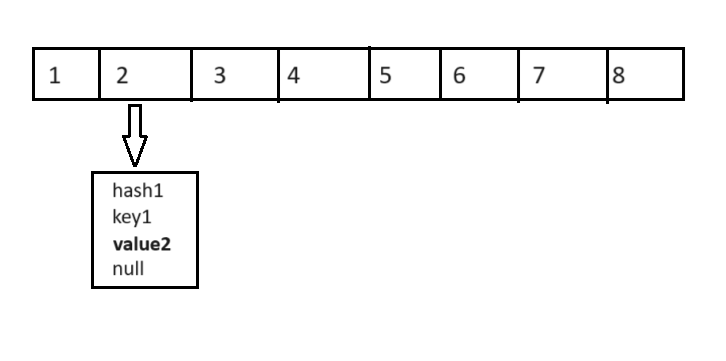
Очень важно, чтобы ключи в HashMap были immutable (неизменными). Ведь если ключ меняется после того, как он был добавлен в HashMap, это может нарушить распределение элементов по бакетам. Ведь у нового ключа уже будет вычислен новый хеш код, но элемент находится в ячейке по старому хеш коду. Это приведет к тому, что объект станет недоступным, либо будут нарушены правила сравнения в бакете.
Роль метода hashCode() та equals()
Переопределение методов hashCode() и equals() и понимание контракта между ними являются критически важными для корректной работы с HashMap и других хешированных структур данных.
Роль hashCode()
Метод hashCode() отвечает за вычисление хеш-кода объекта, который используется для определения его места в массиве бакетов. Этот хеш-код затем трансформируется в индекс массива, где будет храниться соответствующая пара “ключ-значение”. В идеальном случае, хорошо реализованный метод hashCode() равномерно распределяет элементы по всему массиву, уменьшая количество коллизий и повышая эффективность операций добавления и поиска.
Роль equals()
Метод equals() используется для сравнения ключей при поиске или замене элементов в HashMap. Если два ключа имеют одинаковый хэш-код (то есть попадают в один и тот же бакет), equals() определяет, являются ли эти ключи действительно одинаковыми, и следует ли заменить существующее значение или добавить новый элемент в цепочку.
Основные операции в HashMap
HashMap предоставляет несколько ключевых операций, которые позволяют эффективно работать с данными, организованными в виде пар “ключ-значение”. Рассмотрим основные операции и их особенности:
- Добавление элементов: метод put(K key, V value):
Этот метод используется для добавления новой пары “ключ-значение” в HashMap или для обновления значения существующего ключа. Если ключ уже существует в карте, старое значение заменяется новым. В случае коллизии, когда несколько ключей имеют одинаковый хеш-код и, соответственно, попадают в один бакет, новый элемент добавляется в цепочку внутри этого бакета.
- Получение значений: метод get(Object key):
Этот метод возвращает значение по ключу. Если ключ присутствует в карте, возвращается соответствующее значение. Если же ключа нет в карте, метод возвращает null. Важно отметить, что возвращение null может означать как отсутствие ключа, так и то, что значение, ассоциированное с этим ключом, равно null.
- Удаление элементов: метод remove(Object key):
Этот метод удаляет из HashMap пару “ключ-значение” по заданному ключу. Если ключ присутствует, он удаляется вместе с соответствующим значением, и структура карты корректируется соответственно. Если же ключа нет, метод ничего не меняет в структуре.
- Проверка наличия ключа: метод containsKey(Object key):
Этот метод проверяет, содержит ли HashMap определенный ключ. Возвращает true, если ключ есть в карте, и false, если ключ отсутствует.
- Проверка наличия значения: метод containsValue(Object value):
Этот метод проверяет, содержит ли HashMap определенное значение.
- Получение размера: метод size():
Этот метод возвращает количество пар “ключ-значение”, хранящихся в HashMap.
- Перебор значений:
HashMap предоставляет несколько способов перебора пар “ключ-значение”. Наиболее распространенные способы включают в себя:
- Перебор с помощью entrySet(): Вы можете использовать цикл for-each для перебора всех пар “ключ-значение” в HashMap:
for (Map.Entry<K, V> entry : map.entrySet()) {
K key = entry.getKey();
V value = entry.getValue();
// Выполняйте нужные действия с ключом и значением
}- Перебор ключей с помощью keySet(): Можно перебирать только ключи
for (K key : map.keySet()) {
V value = map.get(key);
// Выполняйте нужные действия с ключом и значением
}- Перебор значений с помощью values(): Можно перебирать только значения
for (V value : map.values()) {
// Выполняйте нужные действия со значением
}Порядок перебора элементов в HashMap не гарантирован и может меняться. Это связано с тем, что HashMap не хранит элементы в каком-то определенном порядке (например, по времени добавления или по порядку ключей). Если вам важен порядок, рассмотрите использование других коллекций, таких как LinkedHashMap.
Заключение
HashMap является одной из самых эффективных и распространенных структур данных для хранения и быстрого доступа к парам “ключ-значение”. Благодаря своей внутренней структуре, основанной на массиве бакетов и хешировании, HashMap обеспечивает среднюю сложность операций O(1) для добавления, получения и удаления элементов, что делает ее незаменимой во многих приложениях.

У вас остались вопросы о hashmap в Java? Спрашивайте в комментариях ниже.